搜索到
53
篇与
的结果
-
HTML两栏实现左侧内容可滚动,右侧列表固定跟随布局 HTML实现左侧内容可滚动,右侧列表固定布局<!doctype html> <html> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1, maximum-scale=1, user-scalable=no"> <title>HTML实现左侧内容可滚动,右侧列表固定布局</title> <style type="text/css"> html,body{ width:100%; height:100%; } html,body,header,footer,div,section{ padding:0; margin:0; } .clearfix:after{ content:''; display:block; clear:both; height:0; visibility:hidden; } .clearfix{ zoom:1; } .sec-wrapper{ min-height:100%; } .head-top{ width:100%; height:100px; line-height:100px; text-align:center; font-size:16px; color:#fff; background:#E74445; } .main-section{ padding-bottom:100px; margin:20px auto; } .foot{ width:100%; height:100px; line-height:100px; text-align:center; font-size:16px; color:#fff; background:#528FEA; margin-top:-100px; } .div-wrapper{ width:1200px; margin:0 auto; background:#F4F6F9; position:relative; } .cont-left{ width:900px; float:left; margin-right:10px; } .list-right{ float:left; } .cont-item{ width:100%; height:200px; background:tan; margin-top:10px; } .box-fixed{ width:290px; height:600px; padding-top:20px; background-color:#89A1C5; position:relative; top:0px; text-align:center; color:#fff; } .tab_fix_bottom { position: absolute; bottom: 0px; top: auto; } .tab_fix{ position:fixed; } </style> </head> <body> <section class="sec-wrapper"> <header class="head-top">页面头部</header> <section class="main-section"> <div class="div-wrapper clearfix"> <div class="cont-left"> <div class="cont-item"></div> <div class="cont-item"></div> <div class="cont-item"></div> <div class="cont-item"></div> <div class="cont-item"></div> <div class="cont-item"></div> <div class="cont-item"></div> <div class="cont-item"></div> </div> <div class="list-right"> <div class="box-fixed">新闻列表</div> </div> </div> </section> </section> <footer class="foot">页面底部</footer> <script src="/style/js/jquery-2.1.1.min.js"></script> <script type="text/javascript"> $(function(){ var fheight = $('.foot').height() + 30; // 获取底部及底部上方边距的总高度 var boxfixed = $('.box-fixed'); // 获取固定容器的jquery对象 $(window).scroll(function() { var scrollTop = $(window).scrollTop(); // 获取滚动条滚动的高度 var contLeftTop = $('.cont-left').offset().top+20; // 右侧列表相对于文档的高度 var scrollBottom = $(document).height() - $(window).scrollTop() - boxfixed.height(); if (scrollTop >= contLeftTop) { if (scrollBottom > fheight) { // 滚动条距离底部的距离大于fheight,添加tab_fix类,否则添加tab_fix_bottom类 boxfixed.removeClass("tab_fix_bottom").addClass('tab_fix'); } else { boxfixed.removeClass('tab_fix').addClass("tab_fix_bottom"); } } else if (scrollTop < contLeftTop) { boxfixed.removeClass('tab_fix').removeClass("tab_fix_bottom"); } }); }); </script> </body> </html>
-
 Python 爬取YouTube某个频道下的所有视频信息 被生活安排了这么一个需求。 需要爬取YouTube给的频道下的给定日期范围内的视频的信息,如标题,点赞数,点踩数,播放量等信息 首先需要一个谷歌账号,翻墙工具来科学上网,打开YouTube,搜索指定的频道,进入频道界面 然后查看网页源代码,搜索channel,得到频道的频道ID 然后还需要申请谷歌数据API的个人独有的API key,参照博客申请api key并指定YouTube api 下面是谷歌的api地址 self.app_key = '你自己的 api key'self.channel_api = 'https://developers.google.com/apis-explorer/#p/youtube/v3/youtube.channels.list?part=snippet,contentDetails&publishedAfter=2016-11-01T00:00:00Z&publishedBefore=2017-12-31T00:00:00Z&id='+ channel_id + '&key=' + self.app_keyself.info_api = 'https://www.googleapis.com/youtube/v3/videos' 本来的思路是找出所有的视频地址,然后根据视频发布日期过滤结果,而恰巧谷歌限制了API的返回结果为500个(实际为500个左右),导致视频缺失,导致我思考了很久解决办法,最终还是Google到了结果(Google google的问题 = =) 相关摘录: “如果没有搜索结果的质量严重降低(重复等),我们无法通过API为任意YouTube查询提供超过500个搜索结果. v1 / v2 GData API在11月更新,以限制返回到500的搜索结果数.如果指定500或更高的起始索引,则不会获得任何结果. 因此,为了获取全部指定时间段发布的视频,需要在参数里加上发布日期界限(分时间段搜索,每次的搜索结果上限仍然是500,请特别注意!!!!) publishedAfter=2016-11-01T00:00:00Z&publishedBefore=2017-12-31T00:00:00Z 下面贴完整代码: # -*- coding: UTF-8 -*- import urllib2 import time import urllib import json import datetime import requests import sys import xlsxwriter reload(sys) sys.setdefaultencoding("utf-8") channel = "Samsung"#频道名 channel_id = 'UCWwgaK7x0_FR1goeSRazfsQ'#频道ID class YoukuCrawler: def __init__(self): self.video_ids = [] self.maxResults = 50#每次返回的结果数 self.app_key = '你自己的 api key' self.channel_api = 'https://developers.google.com/apis-explorer/#p/youtube/v3/youtube.channels.list?part=snippet,contentDetails&publishedAfter=2016-11-01T00:00:00Z&publishedBefore=2017-12-31T00:00:00Z&id='+ channel_id + '&key=' + self.app_key # self.info_api = 'https://www.googleapis.com/youtube/v3/videos?maxResults=50&part=snippet,statistics' + '&key=' + self.app_key self.info_api = 'https://www.googleapis.com/youtube/v3/videos' now = time.mktime(datetime.date.today().timetuple()) def get_all_video_in_channel(self, channel_id): base_video_url = 'https://www.youtube.com/watch?v=' base_search_url = 'https://www.googleapis.com/youtube/v3/search?' first_url = base_search_url + 'key={}&channelId={}&part=snippet,id&publishedAfter=2016-11-01T00:00:00Z&publishedBefore=2017-12-31T00:00:00Z&order=date&maxResults=25'.format(self.app_key, channel_id) url = first_url while True: print url request = urllib2.Request(url=url) response = urllib2.urlopen(request) page = response.read() result = json.loads(page, encoding="utf-8") for i in result['items']: try: self.video_ids.append(i['id']['videoId'])#获取作品ID except: pass try: next_page_token = result['nextPageToken']#获取下一页作品 url = first_url + '&pageToken={}'.format(next_page_token) except: print "no nextPageToken" break def main(self): self.get_all_video_in_channel(channel_id) return self.get_videos_info() def get_videos_info(self):#获取作品信息 url = self.info_api query = '' count = 0 f = open(channel_id + '.txt', 'w') print len(self.video_ids) for i in self.video_ids: try: count += 1 query = i results = requests.get(url, params={'id': query, 'maxResults': self.maxResults, 'part': 'snippet,statistics', 'key': self.app_key}) page = results.content videos = json.loads(page, encoding="utf-8")['items'] for video in videos: try: like_count = int(video['statistics']['likeCount']) except KeyError: like_count = 0 try: dislike_count = int(video['statistics']['dislikeCount']) except KeyError: dislike_count = 0 temp = time.mktime(time.strptime(video['snippet']['publishedAt'], "%Y-%m-%dT%H:%M:%S.000Z")) dateArray = datetime.datetime.utcfromtimestamp(int(temp)) otherStyleTime = dateArray.strftime("%Y-%m-%d") print otherStyleTime,count if (otherStyleTime>='2016-11-01' and otherStyleTime
Python 爬取YouTube某个频道下的所有视频信息 被生活安排了这么一个需求。 需要爬取YouTube给的频道下的给定日期范围内的视频的信息,如标题,点赞数,点踩数,播放量等信息 首先需要一个谷歌账号,翻墙工具来科学上网,打开YouTube,搜索指定的频道,进入频道界面 然后查看网页源代码,搜索channel,得到频道的频道ID 然后还需要申请谷歌数据API的个人独有的API key,参照博客申请api key并指定YouTube api 下面是谷歌的api地址 self.app_key = '你自己的 api key'self.channel_api = 'https://developers.google.com/apis-explorer/#p/youtube/v3/youtube.channels.list?part=snippet,contentDetails&publishedAfter=2016-11-01T00:00:00Z&publishedBefore=2017-12-31T00:00:00Z&id='+ channel_id + '&key=' + self.app_keyself.info_api = 'https://www.googleapis.com/youtube/v3/videos' 本来的思路是找出所有的视频地址,然后根据视频发布日期过滤结果,而恰巧谷歌限制了API的返回结果为500个(实际为500个左右),导致视频缺失,导致我思考了很久解决办法,最终还是Google到了结果(Google google的问题 = =) 相关摘录: “如果没有搜索结果的质量严重降低(重复等),我们无法通过API为任意YouTube查询提供超过500个搜索结果. v1 / v2 GData API在11月更新,以限制返回到500的搜索结果数.如果指定500或更高的起始索引,则不会获得任何结果. 因此,为了获取全部指定时间段发布的视频,需要在参数里加上发布日期界限(分时间段搜索,每次的搜索结果上限仍然是500,请特别注意!!!!) publishedAfter=2016-11-01T00:00:00Z&publishedBefore=2017-12-31T00:00:00Z 下面贴完整代码: # -*- coding: UTF-8 -*- import urllib2 import time import urllib import json import datetime import requests import sys import xlsxwriter reload(sys) sys.setdefaultencoding("utf-8") channel = "Samsung"#频道名 channel_id = 'UCWwgaK7x0_FR1goeSRazfsQ'#频道ID class YoukuCrawler: def __init__(self): self.video_ids = [] self.maxResults = 50#每次返回的结果数 self.app_key = '你自己的 api key' self.channel_api = 'https://developers.google.com/apis-explorer/#p/youtube/v3/youtube.channels.list?part=snippet,contentDetails&publishedAfter=2016-11-01T00:00:00Z&publishedBefore=2017-12-31T00:00:00Z&id='+ channel_id + '&key=' + self.app_key # self.info_api = 'https://www.googleapis.com/youtube/v3/videos?maxResults=50&part=snippet,statistics' + '&key=' + self.app_key self.info_api = 'https://www.googleapis.com/youtube/v3/videos' now = time.mktime(datetime.date.today().timetuple()) def get_all_video_in_channel(self, channel_id): base_video_url = 'https://www.youtube.com/watch?v=' base_search_url = 'https://www.googleapis.com/youtube/v3/search?' first_url = base_search_url + 'key={}&channelId={}&part=snippet,id&publishedAfter=2016-11-01T00:00:00Z&publishedBefore=2017-12-31T00:00:00Z&order=date&maxResults=25'.format(self.app_key, channel_id) url = first_url while True: print url request = urllib2.Request(url=url) response = urllib2.urlopen(request) page = response.read() result = json.loads(page, encoding="utf-8") for i in result['items']: try: self.video_ids.append(i['id']['videoId'])#获取作品ID except: pass try: next_page_token = result['nextPageToken']#获取下一页作品 url = first_url + '&pageToken={}'.format(next_page_token) except: print "no nextPageToken" break def main(self): self.get_all_video_in_channel(channel_id) return self.get_videos_info() def get_videos_info(self):#获取作品信息 url = self.info_api query = '' count = 0 f = open(channel_id + '.txt', 'w') print len(self.video_ids) for i in self.video_ids: try: count += 1 query = i results = requests.get(url, params={'id': query, 'maxResults': self.maxResults, 'part': 'snippet,statistics', 'key': self.app_key}) page = results.content videos = json.loads(page, encoding="utf-8")['items'] for video in videos: try: like_count = int(video['statistics']['likeCount']) except KeyError: like_count = 0 try: dislike_count = int(video['statistics']['dislikeCount']) except KeyError: dislike_count = 0 temp = time.mktime(time.strptime(video['snippet']['publishedAt'], "%Y-%m-%dT%H:%M:%S.000Z")) dateArray = datetime.datetime.utcfromtimestamp(int(temp)) otherStyleTime = dateArray.strftime("%Y-%m-%d") print otherStyleTime,count if (otherStyleTime>='2016-11-01' and otherStyleTime -
苹果CMS(MACCMS)如何在标题中随机插入关键词 标题中随机插入关键词是一种常见的黑帽SEO手法。下面就为大家介绍一下,比较受欢迎的影视CMS程序苹果CMS页面标题中如何随机插入关键词: 一、找到文件:根目录 》/application/common.php ,在其底部加入代码如下: function get_keyworks($id){ $keyword = file_get_contents(ROOT_PATH.’keywords/’.$id.’.txt’); if($keyword){ return $keyword; } $filetxt = file_get_contents(ROOT_PATH.’keywords.txt’); $textArray = explode(“\n”, $filetxt); shuffle($textArray); $newArray = array_slice(array_unique($textArray),0,1); //关键词数量 $newKeywords = implode(‘,’,$newArray); file_put_contents(ROOT_PATH.’keywords/’.$id.’.txt’,$newKeywords); return $newKeywords; } 二、根目录创建keywords.txt 一行一个放入自己的关键词 三、然后在application目录建立一个keywords文件夹 四、调用标签(在模板中使用以下标签可以随机调用关键词):{:get_keyworks($obj.vod_id)} 注:以上方法在php 5.6 上实测可用。
-
为你的 WordPress 站点配置 Telegram Instant View Telegram 内置了一个非常好用的阅读功能 —— Instant View。Instant View 可以实现在 Telegram 内部重新对网站内容进行排版,从而为读者提供更好的阅读体验。 作为一个网站主,如果你希望对你的网站提供相应的支持,则可以自行在 Instant View 的网站添加你自己的网站进行适配。 为 WordPress 添加 Instant View 适配 访问 Instant View 官网,并使用你自己的 Telegram 账号登录 Instant View 官网 登录成功后,点击右侧的 My Templates,进入到 Templates 管理页面。 并在 Templates 管理页面中间的输入框中输入你网站任一文章的地址,并回车,你会自动进入到规则的适配页面。 规则适配页面 随后,在页面中输入你的站点的规则,这里我们可以使用其他开发者写好的规则。将规则粘贴在页面中 # Use Instant View version 2.0 ~version: "2.0" # Use this template only blog article pages ?exists: /html/head/meta[@property="article:published_time"] # Get article text in <article> body: //article # Get title from <h1> title: $body//h1[1] subtitle: $title/next-sibling::h2 author_url: //span[has-class("author")]//@href # Get article cover image cover: //img[has-class("wp-post-image")] # Convert all iframe elements to inline element @inline: $body//iframe[starts-with(@src, "/media/")] # Remote header and footer @remove: //article/header @remove: //article/footer # Replace p to figure @replace_tag(<figure>): $body//p[.//img] # Youtube Embedded Fix @replace_tag(<figure>): $body//p[.//iframe] 粘贴并保存后,会自动在最右侧页面生成预览的效果。 加入规则适配后的效果 当你的规则适配效果无误后,接下来只需要点击右上叫的 Mark as Checked ,来标记该页面已经检查完车。 标记为检查成功 测试完成第一个后, 接下来你只需要在你的博客当中挑选出 10 篇文章,进行文章的验证即可。 验证至少 10 个页面才行根据 Telegram Instant View 的规则,你需要验证满 10 篇文章,才能提交你的模板给官方人员审核。提交后,你会见到这样的提示,接下来只需要等待你的模板通过测试即可。提交成功预览效果在审核期间,你可以在编辑器页面右上角点击「View in Telegram」来查看预览的效果。包括你也可以复制里面的 rhash 的值,使用这个值来生成 Instant View 的链接分享给别人。不过,最方便的当然还是等官方审核通过以后再用。预览效果。总结Telegram Instant View 的开发不困难,掌握了一定的 HTML 、XPath 的基础,就可以开发完成,简单的几步,就可以让你的网站在 Telegram 当中拥有一个不错的预览效果,这个时间值得去花。</div>
-
NGINX,PHP获取Cloudflare传递的真实访客IP 配合宝塔面板防御CC攻击 防伪造IP 日志记 Cloudflare获取访客真实IP,获取cf传递的真实访客ip,再结合我们的cdn.bnxb.com的批量提交IP给CF的防火墙的功能,可以实现抵御CC攻击的功能,将CC攻击者的连接IP给封杀在CDN阶段,就到不了我们服务器,消耗不了我们的服务器资源那怎么获取CC攻击者的真实IP信息呢(也就是这些CC攻击者连接到CF CDN的IP),其实很简单,CF有将通过他们的CDN访问你网站的访客的真实IP通过HEADER发送到你服务器来,标头是HTTP_CF_CONNECTING_IPNGINX,PHP获取Cloudflare发送的真实访客IP 可用于防御CC攻击 防伪造IP 日志记录真实IP 显示访客真实IP先看看我们通过PHP 得到的CF返回来的HEADER信息<?php print_r($_SERVER); ?>读取到结果如下:Array ( [USER] => www [HOME] => /home/www [HTTP_CF_CONNECTING_IP] => 122.114.6.211 [HTTP_COOKIE] => __cfduid=*****; PHPSESSID=******; PHPSESSID=*****; Hm_lvt_***=****; Hm_lpvt_*****=1536121476 [HTTP_ACCEPT_LANGUAGE] => zh-CN,zh;q=0.9 [HTTP_ACCEPT] => text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8 [HTTP_USER_AGENT] => Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36 [HTTP_UPGRADE_INSECURE_REQUESTS] => 1 [HTTP_CF_VISITOR] => {"scheme":"https"} [HTTP_X_FORWARDED_PROTO] => https [HTTP_CF_RAY] => 455d1c72ed0e963d-SJC [HTTP_X_FORWARDED_FOR] => 122.114.6.211 [HTTP_CF_IPCOUNTRY] => CN [HTTP_ACCEPT_ENCODING] => gzip [HTTP_CONNECTION] => Keep-Alive [HTTP_HOST] => cdn.bnxb.com [PATH_INFO] => [REDIRECT_STATUS] => 200 [SERVER_NAME] => cdn.bnxb.com [SERVER_PORT] => 443 [SERVER_ADDR] => * [REMOTE_PORT] => 12554 [REMOTE_ADDR] => 172.68.132.93 [SERVER_SOFTWARE] => nginx/1.14.0 [GATEWAY_INTERFACE] => CGI/1.1 [HTTPS] => on [REQUEST_SCHEME] => https [SERVER_PROTOCOL] => HTTP/1.1 [DOCUMENT_ROOT] => / [DOCUMENT_URI] => /ip.php [REQUEST_URI] => /ip.php [SCRIPT_NAME] => /ip.php [CONTENT_LENGTH] => [CONTENT_TYPE] => [REQUEST_METHOD] => GET [QUERY_STRING] => [SCRIPT_FILENAME] => /ip.php [FCGI_ROLE] => RESPONDER [PHP_SELF] => /ip.php [REQUEST_TIME_FLOAT] => 1536196806.1434 [REQUEST_TIME] => 1536196806 )其中HTTP_CF_CONNECTING_IP标头就是我们要的访客真实IP信息了。接下来说一下NGINX和PHP分别如何获取这个IP1、NGINX配置获取CloudFlare 下的访客真实IP并记录到日志需要修改NGINX的配置文件宝塔的nginx配置文件存放位置与一般nginx不一样,宝塔存放nginx配置文件位置:/www/server/nginx/conf/nginx.conf;一般nginx的配置文件位置:/usr/local/nginx/conf/nginx.conf。在http {}部分增加map $HTTP_CF_CONNECTING_IP $clientRealIp { "" $remote_addr; ~^(?P<firstAddr>[0-9.]+),?.*$ $firstAddr; } log_format main '$clientRealIp [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '$http_user_agent $remote_addr $request_time';主要是为了通用性,如果关闭了CDN,可以不需要修改获取IP的方式,所以才这么修改,不然直接用$HTTP_CF_CONNECTING_IP就行了(这个时候就不需要在日志格式里使用$clientRealIp)然后在网站记录的日志定义使用main这个日志格式比如access_log /www/wwwlogs/www.bnxb.com.log main;可以参考https://www.bnxb.com/nginx/27513.html另外还有一种更简单的方法,但是如果服务器上有其他站点没套CF,可能就获取会异常。就是在NGINX的主配置文件中加入set_real_ip_from 0.0.0.0/0;real_ip_header CF-CONNECTING-IP;如下图:2、PHP获取使用CloudFlare CDN环境下的访客真实IP<?php $realip =$_SERVER['HTTP_CF_CONNECTING_IP']; echo $realip; //也可以用下面这个 $clientIP = isset($_SERVER['HTTP_CF_CONNECTING_IP']) ? $_SERVER['HTTP_CF_CONNECTING_IP'] : $_SERVER['REMOTE_ADDR']; echo $clientIP; ?>以上就是获取Cloudflare环境下真实IP功能3、利用宝塔防火墙配合CF CDN防御CC攻击宝塔的防火墙可以打开CDN选项,这样就能获取到CDN后面的真实访客IP,但是需要自定义HEADER先设置一下防御的力度,我是设置30秒60次然后设置下真实访客IP的获取方式添加HEADER,把cf_connecting_ip加进去,原来的x-forwarded-for 和x-real-ip都删掉完工,这样宝塔的防火墙就能利用CF传递过来的真实访客IP对攻击者进行封禁来源:https://www.bnxb.com/php/27592.html
-
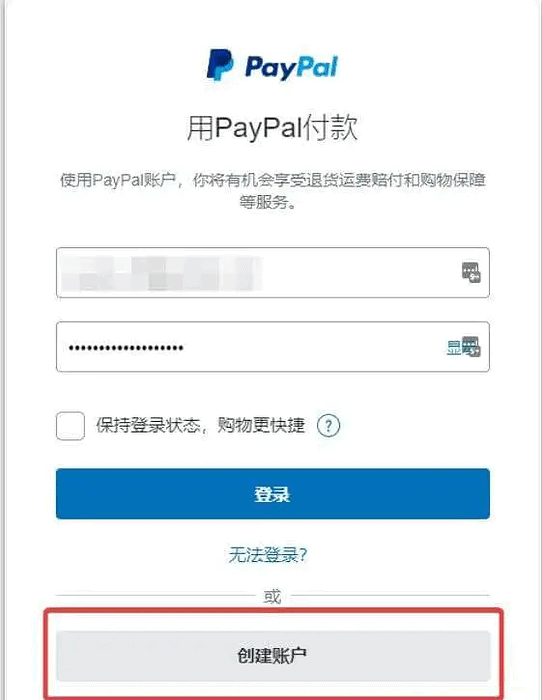
Paypal外区账户/国际版绑大陆手机号注册教程 首先,需要明确的:我们注册Paypal一般是不考虑国区的,也就是贝宝。虽然注册简单,但是在对外使用上限制太多,很不方便。注册外区账户,也就是俗称的国际板。常见的有:港区,美区,台区、日区、新区等等,大体上区别也就2点:1、有些区是有消费税之类的,这点可以在Paypal官网上去看;2、不同区有时候会推出一些不同的活动,比如代金券之类的。如果我们直接到对应区官网注册,会要求必须输入当地手机号并进行验证,而且后期也是没有办法换绑为自己国内手机号的。这一步会难住很多人!一些人虽然能找到接码,可是对账户安全影响很大,毕竟接码的手机号不是自己可控的。这也就是本文所讲的重点:如何用大陆手机号注册Paypal外区账户。注册准备1、干净的IP:没有注册、登陆过已有账户或是被风控账户的IP。本地IP即可,有对应区域的自用IP更好2、干净的浏览器:将浏览器的cookie清空,并开启隐私模式。推荐:Chrome、Firefox、Edge,不建议使用国内浏览器。如果有指纹浏览器更好3、注册使用的邮箱:尽量不要用国内邮箱4、虚假信用卡信息生成:https://www.creditcardvalidator.org/generator5、一张外币信用卡:国内行的卡就行。如果没有的话,也可以暂时不要。但后面要使用时肯定是需要的开始注册1、找一些国外有PayPal支付方式的网站,随便下单,进入到结算页,选择Paypal支付(PP账户注册成功后,付款是要二次确认的,所以不用担心被扣款的情况)。这里博主使用的是阿里云国际,注册完阿里云国际账户后,进入 控制台 — 费用 — 支付方式管理 — Paypal ,点击 绑定 。一般都会跳出一个小窗口页面,进入到Paypal。选择【创建账户】注意:有的Paypal显示的不是创建账户,而是“用信用卡或者借记卡绑定支付”之类,这里选择是一样的。2、跳转到注册信息填写页面,填写要点如下: 国家或地区:这里的选择就决定了你账户属于哪个区域。你如果用的是本地IP,这里就需要手动选择你所想注册的地区;如果是用当地IP,这里就默认会检测出所在地区 信用卡信息:这里卡号信息可以暂填一个假的即可(即便是假的也不能胡编,在虚假信用卡信息生成网站中生成一个填到这),因为不管卡号真假在这都是绑不上的。后面有需要时可以再绑真实的。账单地址就自己在 Goole Maps 中找一个当地地址填入 联系资料中的手机号码:选择 中国+86,填入你的大陆手机号 个人信息:出生国家、国籍都选“中国”,ID信息建议填真实的。后面万一出现风控、纠纷,能够提供有效资料来维护自己权益。除非是你准备只用一次 3、点击【同意并继续】后,一般会跳转到一个绑卡页面(有的也没有这个页面),这个时候直接退出不用绑卡。至此,你的Paypal账户就已经注册完成了!注意事项1、新账户注册成功后,不建议立即验证手机号、绑卡。先放置3-7天,首轮风控期过后再验证手机号,绑卡;2、绑卡后建议先选择个福利项目,进行一个小额捐赠。然后同样再放置一周左右。之后就正常使用即可;3、使用过程中建议不要频繁跳IP,会引起风控。另外补充一点,如果你想看你的账户属于哪一个区,可以登录Paypal后台,进入钱包里,看币种就知道了。比如,香港Paypal就会显示美元与港币,新加坡Paypal就会显示美元与新加坡元。
-
Linux脚本iptables屏蔽指定国家或海外IP恶意访问网站的详细方法 前言:对于网站站长来说,经常遇到海外ip恶意抓取或恶意CC攻击的情况,对于这种问题,很是头痛,之前本站也有一篇教程介绍在Linux系统下使用SH脚本如何屏蔽海外ip的详细方法,虽然可以屏蔽,但功能不强大,本次在网上找到了一篇非常使用的教程,可以屏蔽指定国家的ip访问服务器,现在转载过来,希望对大家有帮助本教程相关阅读:1、Linux系统屏蔽国外(海外)IP解决被CC攻击的方法:https://blog.tag.gg/showinfo-3-36155-0.html2、被CC攻击了怎么办?Linux系统使用shell脚本自动屏蔽简单解决CC攻击方法:https://blog.tag.gg/showinfo-3-36156-0.html 功能:屏蔽指定国家地区的IP访问方法一:使用大神的开源脚本,屏蔽指定国家地区的IP访问执行如下命令下载脚本并执行 wget https://blog.tag.gg/soft/block-ips.shsh block-ips.sh 执行效果如图封禁ip时会要求你输入国家代码,国家代码以及国家对应的ip段可查看:点击进入。记住所填参数均为小写字母。比如JAPAN (JP),我们就输入jp这个参数 方法二:使用IPIP的数据库进行流量屏蔽(推荐,目前已支持centos6和7还有ubuntu系统)1、创建一个shell脚本文件例如block_ip.sh,并写入如下代码保存 #!/bin/bash#判断是否具有root权限root_need() { if [[ $EUID -ne 0 ]]; then echo “Error:This script must be run as root!” 1>&2 exit 1 fi}#检查系统分支及版本(主要是:分支->>版本>>决定命令格式)check_release() { if uname -a | grep el7 ; then release=”centos7″ elif uname -a | grep el6 ; then release=”centos6″ yum install ipset -y elif cat /etc/issue |grep -i ubuntu ; then release=”ubuntu” apt install ipset -y fi}#安装必要的软件(wget),并下载中国IP网段文件(最后将局域网地址也放进去)get_china_ip() { #安装必要的软件(wget) rpm –help >/dev/null 2>&1 && rpm -qa |grep wget >/dev/null 2>&1 ||yum install -y wget ipset >/dev/null 2>&1 dpkg –help >/dev/null 2>&1 && dpkg -l |grep wget >/dev/null 2>&1 ||apt-get install wget ipset -y >/dev/null 2>&1 #该文件由IPIP维护更新,大约一月一次更新(也可以用我放在国内的存储的版本,2018-9-8日版) [ -f china_ip_list.txt ] && mv china_ip_list.txt china_ip_list.txt.old wget https://github.com/17mon/china_ip_list/blob/master/china_ip_list.txt cat china_ip_list.txt |grep ‘js-file-line”>’ |awk -F’js-file-line”>’ ‘{print $2}’ |awk -F'< ‘ ‘{print $1}’ >> china_ip.txt rm -rf china_ip_list.txt #wget https://qiniu.wsfnk.com/china_ip.txt #放行局域网地址 echo “192.168.0.0/18” >> china_ip.txt echo “10.0.0.0/8” >> china_ip.txt echo “172.16.0.0/12” >> china_ip.txt}#只允许国内IP访问ipset_only_china() { echo “ipset create whitelist-china hash:net hashsize 10000 maxelem 1000000” > /etc/ip-black.sh for i in $( cat china_ip.txt ) do echo “ipset add whitelist-china $i” >> /etc/ip-black.sh done echo “iptables -I INPUT -m set –match-set whitelist-china src -j ACCEPT” >> /etc/ip-black.sh #拒绝非国内和内网地址发起的tcp连接请求(tcp syn 包)(注意,只是屏蔽了入向的tcp syn包,该主机主动访问国外资源不用影响) echo “iptables -A INPUT -p tcp –syn -m connlimit –connlimit-above 0 -j DROP” >> /etc/ip-black.sh #拒绝非国内和内网发起的ping探测(不影响本机ping外部主机) echo “iptables -A INPUT -p icmp -m icmp –icmp-type 8 -j DROP” >> /etc/ip-black.sh #echo “iptables -A INPUT -j DROP” >> /etc/ip-black.sh rm -rf china_ip.txt}run_setup() { chmod +x /etc/rc.local sh /etc/ip-black.sh rm -rf /etc/ip-black.sh #下面这句主要是兼容centos6不能使用”-f”参数 ipset save whitelist-china -f /etc/ipset.conf || ipset save whitelist-china > /etc/ipset.conf [ $release = centos7 ] && echo “ipset restore -f /etc/ipset.conf” >> /etc/rc.local [ $release = centos6 ] && echo “ipset restore < /etc/ipset.conf” >> /etc/rc.local echo “iptables -I INPUT -m set –match-set whitelist-china src -j ACCEPT” >> /etc/rc.local echo “iptables -A INPUT -p tcp –syn -m connlimit –connlimit-above 0 -j DROP” >> /etc/rc.local echo “iptables -A INPUT -p icmp -m icmp –icmp-type 8 -j DROP” >> /etc/rc.local #echo “iptables -A INPUT -j DROP” >> /etc/rc.local}main() { check_release get_china_ip ipset_only_chinacase “$release” incentos6) run_setup ;;centos7) chmod +x /etc/rc.d/rc.local run_setup ;;ubuntu) sed -i ‘/exit 0/d’ /etc/rc.local run_setup echo “exit 0” >> /etc/rc.local ;;esac}main 2、输入命令 block_ip.sh 执行脚本即可。希望对大家有帮助
-
利用腾讯云轻量服务器+宝塔快速搭建负载均衡网站 为什么网站需要负载均衡网站作为一个开放性的事物,在流量大了之后,单一一台服务器往往无法承受住海量的用户,从而导致站点卡顿,或者服务掉线等情况。而负载均衡能够有效的解决这一问题。通过一台主服务器和N个副服务器可以将网站的流量合理的分配至各个副服务器,如果副服务器仍旧处理不了则可以通过添加更多的副服务器来进一步扩容。等待流量高峰期结束再删除掉副服务器节省成本开支。利用腾讯云轻量服务器部署一个高可用服务器选购服务器腾讯云轻量服务器性价比高,香港服务器带宽也有30M,对国内用户体验较好,价格适中,因此此次就用3台香港服务器进行搭建测试。原理简述用户通过浏览器对服务器发出请求——主服务器通过轮询|cookie|iphash 访问其中一台副服务器发出响应的请求——被请求的副服务器处理好网页数据传回主服务器——主服务器返回该数据给用户。其中主服务器在整个过程之中只起到流量转发的作用,相对来说负载较小,副服务器作为负载均衡节点承担着处理数据的作用,负载较大,可以通过增加负载均衡节点(副服务器)来减小服务器负载。备份服务器承担着网站文件备份和应急备用的功能。限制及解决方案:由于用户请求网页到能够看到网页中间这一时长受主服务器与负载均衡节点(副服务器)影响较大,主服务器与节点之间的延时不宜过大,且为了安全考虑尽可能的选择内网互通的服务器做负载均衡。准备事项1、3台尽可能同地区的服务器,1台主服务器,2台副服务器,有条件的可以再加一台备份服务器。这里以三台腾讯云香港轻量服务器34元套餐1C2G作为演示。因为腾讯云轻量服务器在同一账号下同一地区开通的都可以内网互通且内网带宽1.5Gbps三台服务器内网IP分别为:主服务器:10.0.0.8 公网IP假设为124.124.124.124节点1:10.0.0.3节点2:10.0.0.72、宝塔专业版(或主服务器单独购买负载均衡插件)宝塔专业版优惠购买链接 https://www.bt.cn/?invite_code=MV9hbHRmcnY=也可以使用appnode进行操作,appnode免费版即可,但是限制网站数量,操作上会有不同但是理解原理了其实都一样查看不清楚的可以看我博客这篇介绍文章,里面有几个常见面板的使用界面截图除了宝塔之外还有什么网站面板比较好用?附带演示地址搭建负载均衡1、解析域名、搭建网站应用首先域名解析到主服务器公网IP(124.124.124.124)上,然后进入主服务器的宝塔操作面板,首先安装网站应用,这里以typecho(一个轻量级博客系统)为例。打开主服务器宝塔软件商城——宝塔插件——安装宝塔一键部署源码安装完成后点击设置进入下图页面并点击博客——typecho一键部署填写网站信息,我这里以tx01.2demo.top为例填完提交即可然后进入网站首页进行信息填入,注意数据库地址填主服务器内网地址(10.0.0.8)其他的这里就不赘述了。2、配置安全组及负载均衡节点网站配置先在负载均衡节点1、2上配置同样的网站环境然后将刚刚配置好的主服务器上的tx01.2demo.top网站打包上传到负载均衡节点之上。打包主服务器网站打包完成后下载下来然后在负载均衡节点创建网站 tx01.2demo.top注意不用创建数据库进入网站目录——上传刚才从主服务器下载下来的压缩包并解压进入网站设置,配置伪静态规则(宝塔自带typecho规则,选中保存即可),添加ssl证书(其他证书——复制粘贴主服务器的证书然后保存即可)PS:两个节点(副服务器)都需要进行以上配置配置安全组进入腾讯云轻量服务器管理面板选择主服务器——防火墙——添加规则——MySQL打开主服务器宝塔面板页面——安全,放行MySQL端口然后还要再设置一下MySQL权限主服务器宝塔面板——数据库——指定IP——127.0.0.1,10.0.0.3(节点1内网IP),10.0.0.7(节点2内网IP)(用英文逗号隔开)3、配置主服务器负载均衡安装宝塔负载均衡插件软件商城——专业版插件——宝塔负载均衡安装完成后进入设置页面依次填入网站信息添加节点先在节点服务器网站下创建自己的验证文件比如2demo.txt,随便什么文件不用写内容节点地址填节点内网IP配置完成后就可以正式使用了,为了验证是否成功,你可以先把会话跟随关闭,再在节点服务器上随便创建一个HTML页面或者文件进行查看,我这里提供一个简单的HTML文件效果如下,可以上传到节点网站根目录下,然后修改一下节点对于的数字再多刷新几下就能知道相对应的节点是否配置完成了。下拉到最后下载。节点管理还能调整权重、关闭节点等操作这里不做介绍。下面来对比一下单节点和双节点的差距。测试页面为http://tx01.2demo.top/index.php/archives/3/默认主题,文章为纯文字,字数11496个。测试工具为https://loader.io/测试配置为每分钟总共有多少客户端发起请求结论单节点极限为2750/m 此时会出现部分请求出错及超时双节点极限为5750/m 此时会出现部分请求出错及超时数据对比图负载均衡对网站的意义负载均衡是一个好东西,对于小网站来说或许没什么,但是对于大流量网站来说负载均衡是必备的,否则去哪找那么强的一台独立服务器能够让几万十几万的人同时在线呢,对于中小网站也可以用负载均衡来让服务在线时间做一定的保障当一个节点发生故障后不会立刻停止服务,还能快速扩容应对突发流量。要是担心主服务器会挂那就直接再上一个服务器做次要的主服务器,负载均衡节点不用变化,但是这样最好用单独的数据库,这样四台机器一个数据库就能组成一个稳定性极高的服务应用了。以下为详细数据双节点测试图:250500100020005000550057506000双节点测试图:25050010002000250027503000验证文件使用方法:上传到节点网站根目录,修改节点名称 访问 你的域名\2demo.html链接:https://pan.baidu.com/s/1y8H24ZNHAu07EFcrEZ7CSw提取码:demo复制这段内容后打开百度网盘手机App,操作更方便哦
-
如何快速搭建自己的 IPFS 网关 什么是 IPFS星际文件系统(InterPlanetary File System,缩写为 IPFS)是一个旨在实现文件的分布式存储、共享和持久话的网络传输协议。它是一个内容可寻址的点对点超媒体分发协议。在IPFS网络中的节点构成一个分布式文件系统。IPFS GatewayIPFS 网关 (gateway) 允许访问者通过 HTTP 请求从 IPFS 网络访问数据。默认情况下,IPFS 网关配置在 8080 端口上,数据将通过以下方式从正在运行 IPFS 的服务器上获取:http://{your_ip_address}:8080/ipfs/{content ID} or https://{gateway URL}/ipfs/{content ID}/{optional path to resource} 关于 IPFS 网关更详细的介绍: https://docs.ipfs.io/concepts/ipfs-gateway/#overview 27官方推荐配置 IPFS 网关教程: This tutorial configuring an IPFS gateway on a Google Cloud platform其他参考链接:Introduction to IPFS: Run Nodes on Your Network, with HTTP Gateways: https://rossbulat.medium.com/introduction-to-ipfs-set-up-nodes-on-your-network-with-http-gateways-10e21ea689a4 10Cloudflare IPFS gateway: Setting up a Server: https://developers.cloudflare.com/distributed-web/ipfs-gateway/setting-up-a-server/ 8在 Linux 服务器上安装 IPFS官方安装教程详见: https://docs.ipfs.io/install/command-line/#official-distributions 15此处以阿里云 ECS 服务器为例,选择 CentOS 8.5 操作系统。 首先点击 “远程连接”,选择 Workbench 远程连接,通过网页远程访问你的 ECS 实例image.jpg2098×616 125 KB 连接服务器之后,可以通过以下两种方式从 dist.ipfs.io 5 安装 IPFS: 1. 手动安装 go-ipfscd ~/ wget https://dist.ipfs.io/go-ipfs/v0.12.2/go-ipfs_v0.12.2_linux-amd64.tar.gz // 阿里云服务器可能无法访问 dist.ipfs.io // 作为替代,可以使用 wget -q https://github.com/ipfs/go-ipfs/releases/download/v0.12.2/go-ipfs_v0.12.2_linux-amd64.tar.gz // 解压文件夹 tar xvfz go-ipfs_v0.4.18_linux-amd64.tar.gz > x go-ipfs/install.sh > x go-ipfs/ipfs > x go-ipfs/LICENSE > x go-ipfs/LICENSE-APACHE > x go-ipfs/LICENSE-MIT > x go-ipfs/README.md // 进入 go-ipfs 文件夹,运行安装脚本 cd go-ipfs sudo ./install.sh > Moved ./ipfs to /usr/local/bin // 测试 ipfs 是否被正确安装 ipfs --version > ipfs version 0.12.2 2. 通过 ipfs-update 安装cd ~/ wget https://dist.ipfs.io/ipfs-update/v1.8.0/ipfs-update_v1.8.0_linux-amd64.tar.gz tar xvfz ipfs-update_v1.5.2_linux-amd64.tar.gz cd ipfs-update sudo ./install.sh ipfs-update versions ipfs-update install latest 运行 ipfs-update install latest 将安装最新版本的 go-ipfs,返回如下:fetching go-ipfs version v0.4.22 binary downloaded, verifying... success! tests all passed. stashing old binary installing new binary to /usr/local/bin/ipfs checking if repo migration is needed... Installation complete! Remember to restart your daemon before continuing 初始化仓库官方初始化与操作教程详见: https://docs.ipfs.io/how-to/command-line-quick-start/#initialize-the-repository 6安装成功后,首先运行 ipfs init 初始化仓库 (repository) 。IPFS 默认将所有设置和内部数据都放在名为 repository 的目录中。返回如下:ipfs init > initializing ipfs node at /Users/jbenet/.ipfs > generating 2048-bit RSA keypair...done > peer identity: Qmcpo2iLBikrdf1d6QU6vXuNb6P7hwrbNPW9kLAH8eG67z > to get started, enter: > > ipfs cat /ipfs/QmYwAPJzv5CZsnA625s3Xf2nemtYgPpHdWEz79ojWnPbdG/readme 注意事项: 如果运行 sudo ipfs init,将为 root 用户而不是你的本地用户帐户创建存储库。IPFS 不需要 root 权限,所以最好以普通用户身份运行所有命令!使用 Systemd 来启动 IPFS 守护进程Systemd 是大多数较新的 Linux 发行版附带的套件,允许用户创建和管理后台服务。这些服务在服务器启动时自动启动,如果失败则重新启动,并将其输出日志保存到磁盘。创建以下 systemd 单元文件以在重启期间保持 IPFS 服务器的启动: 输入命令 sudo bash -c 'cat >/lib/systemd/system/ipfs.service
-
WordPress不同分类调用不同模板,不同分类下调用不同文章页模板 PS:在wordpress4.4.2上测试可用使用过帝国CMS和织梦DEDEcms建站的朋友都知道,我们可以为不同的分类列表调用不同的分类列表模板样式,不同分类下的文章使用不同的文章页面样式!这样感觉网站大气有个性,下面我来给大家介绍wordpress主题不同分类显示不同样式模板具体步骤.WordPress不同分类使用不同列表模板样式:方法一:创建独立ID或别名的样式文件WordPress默认的分类是查找对应ID的主题文件,找不到就会指向archive.php文件,如果archive.php文件不存在,就会默认使用index.php文件。到博客后台查看一下要设计样式的分类的ID,假设分类ID为7,之后把主题文件archive.php复制一下,把文件改名为:category- 7.php,这样当你浏览分类ID为7的分类时,就会自动调用category-7.php主题文件,就实现了自定义显示分类为7的样式。上面是根据ID来创建文件,其实也可以通过别名来创建,比如id为7的分类别名为Internet,那么创建一个名为category-Internet.php的文件,效果和category-7.php是一样的。当然了,你创建的category-7.php或category-Internet.php的样式要区别于archive.php哦,要不然,就称不上“不同分类使用不同列表样式”了,呵呵方法二:判断ID调用不同样式的文件:上面的方法比较有局限性,如果要实现多个分类列表调用同一个列表模板样式,就需要创建多个文件,此时我们可以使用is_category 这个函数!首先,我们创建两个以上的不同样式的列表文件,比如这里创建article_list.php(文章列表模板样式)、thumb_list.php(有缩略图的列表模板样式)和image_list.php(图集列表样式),然后创建一个archive.php文件,在archive.php中使用下面的代码实现不同的效果。例如:1)要实现id为5的分类使用的是image_list.php样式,其余的使用article_list.php样式,代码如下:2)要实现id为8、9、10这三个分类都使用thumb_list.php样式,其余的使用article_list.php样式呢?可以通过数组实现,以此类推,具体代码如下:3)要实现id为8、9、10三个分类使用thumb_list.php样式,id为1、2、3的分类使用image_list.php样式,其余使用article_list.php样式,可以使用elseif实现,代码如下:小结:上面两种方法都可以实现WordPress不同分类使用不同列表样式,大家可以根据自己需要来选择,奇芳阁更加倾向于方法二,因为通过数组调用,只要给主题设置后台添加一个填写分类id数组的表单,就可以让主题使用者方便地设置啦。WordPress不同分类下的文章使用不同文章样式:WordPress不同分类下的文章使用不同文章模板样式实现的方法和上面说到的方法二的原理是一样的,只不过使用的函数不是is_category ,而是 in_category 。同样我们要根据需要创建两个以上的文章模板样式,比如single1.php、single2.php和single3.php,然后在single.php通过in_category 判断代码来实现自己需要的效果。比如要实现id为8、9、10三个分类下的文章使用single1.php样式,id为1、2、3的分类下的文章使用single2.php样式,其余使用single3.php样式!首先,复制三个single.php文件分别取名为“single1.php”、“single2.php”和“single3.php”,然后,把原先的single.php文件里面的内容全部删除,并用下面的代码进行替换:好了,基本的思路就是这样,最后的总结只有一句:分类页判断分类用is_category(), 内容页判断分类需用in_category()。